 域名频道资讯站
域名频道资讯站曾经,云计算的出现让万物上云,改变了企业传统IT模式与架构。今天,生成式AI技术蓬勃发展带来新变化:智能对话、PPT生成、数字人、医疗大模型……凭借高效的生产力与简单的交互方式,生成式AI正加速改变人们的生产生活。这一趋势,在每年一度的全球科技领域盛宴——亚马逊云科技re:Invent 全球大会上表现的尤为明显。
日前举办的亚马逊云科技2024 re:Invent全球大会上,从数万名与会者关注的话题,到亚马逊云科技发布的新产品与技术,再到展区内亮点展位,生成式AI都是热门与重点。
当观众惊叹于亚马逊发布的新一代基础系列模型Amazon Nova——包含超快速文生视频和多模态模型,在多种任务上展现出顶尖智能和行业领先的性价比,又或者被展区里全球首个由两个AI驱动的全息投影之间的生成式对话惊叹,徜徉在生成式AI能力构建的模型都市中,见证生成式AI如何帮助制造商提升生产效率与质量。
繁花锦簇的应用之下,作为这一切的坚实底座——亚马逊云科技的基础设施创新显得尤为重要。
计算核心变革:纵向提升与横向扩展
大模型训练与推理带来AI算力需求激增,我们需要怎样的算力?
首先,纵向来看,大模型对算力性能的提升需求迫切,全球“一卡难求”的景象也充分证明:芯片与服务器是计算变革的核心。
正因如此,亚马逊云科技在大会首日进行了重磅发布:“为AI而生的”芯片Trainium2,以及基于它构建的Trainium加速器及服务器。
 大会现场将Amazon Trainium2服务器搬上主舞台
大会现场将Amazon Trainium2服务器搬上主舞台
据介绍,Trainium2可以说为AI而生,采用了先进的封装技术,将计算芯片和高带宽内存(HBM)模块集成在一个紧凑的封装(package)内。每个Trainium2加速器(单卡)内封装中有两个Trainium2计算核心,而每个核心旁边都配备了两块HBM内存模块,从而实现了计算和内存的无缝集成。这种先进的封装设计克服了芯片尺寸的工程极限,最大限度地缩小了计算和内存之间的距离,使用大量高带宽、低延迟的互连将它们连接在一起。这不仅降低了延迟,还能使用更高效的协议交换数据,提高了性能。Trainium2还将电压调节器移至封装周围,靠近芯片本身,通过更短的导线为芯片供电,减少了电压下降,提高了能效。
Amazon EC2 Trn2服务器和Amazon EC2 Trn2 UltraServers超级服务器都是为AI负载和设计,对大模型推理与训练提供更优性能,并提供快速扩展能力。

每台Trainium服务器搭载16块Trainium加速器,并配备有专用的Nitro加速卡和机头。一台Trainium服务器可提供20.8千万亿次每秒浮点运算能力,是亚马逊云科技当前最大AI服务器的1.25倍。同时,它还拥有1.5TB的高速HBM内存,是现有最大AI服务器的2.5倍,显存带宽达46TB/s。
与当前基于GPU的EC2 P5e和P5en实例相比,Amazon EC2 Trn2实例的性价比提升30-40%。
全新推出的Amazon EC2 Trn2 UltraServers服务器机型配备64个相互连接的Trainium2芯片,采用NeuronLink超速互连技术,可提供高达83.2 Petaflops浮点算力,其计算、内存和网络能力是单一实例的四倍,能够支持训练和部署超大规模的模型。亚马逊云科技高级副总裁Peter DeSantis这样评价:“如果你要构建一个万亿参数的AI模型,这就是你需要的那种服务器。”
此外,亚马逊云科技还在会上发布了新一代AI训练芯片Amazon Trainium3,这是亚马逊云科技首款采用3纳米工艺制造的芯片,在性能、能效和密度上树立了新标杆,大会预告首批基于Trainium3的实例计划在2025年末上线。
其次,Scaling laws仍然是大模型预训练第一性原理,算力的横向扩展能力对AI仍然十分关键。
大模型参数从十亿到百亿、千亿、万亿跨越,尽管高性能芯片不断演进,需要的计算集群规模仍然日趋扩大, 千卡、万卡计算集群层出不穷,其构建并非简单的芯片堆叠,而是需要极强的网络互联能力。
为此,亚马逊云科技在会上推出了”10p10u”网络,以及SIDR全新网络路由协议。
“10p10u”网络即第二代UltraCluster网络架构,支持超过20,000个GPU协同工作,因带宽达10Pb/s,延迟低于10ms而得名,可将模型训练时间缩短至少15%。
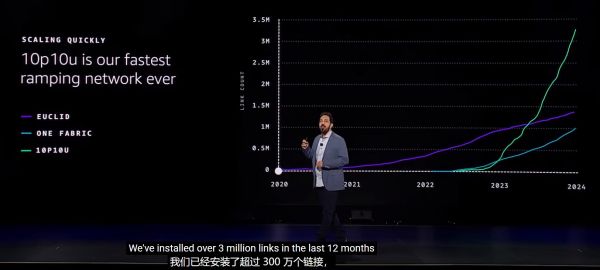
10p10u成为亚马逊云科技有史以来扩展最快的网络
10p10u实现了多项创新:将16根单独光线电缆组成一个单一的连接器,从而将复杂的组装在工厂完成,能够加快54%的安装到机架上的时间;提供定制的光纤插头和光纤电缆,能够在机架到达数据中心前进行全面的测试和验证网络连接,从而消除调试布线的时间,同时还提供保护密封,防止灰尘颗粒进入光纤接口。据悉,10p10u在过去的12个月里安装了超过300万条链路,成为亚马逊云科技有史以来扩展最快的网络。
SIDR(Scalable, Intent Driven Routing)全新网络路由协议,兼具中央控制和优化及分布式的速度和弹性。专为解决AI网络中光链路故障频发、路由更新缓慢的问题而设计。它结合了集中规划的全局控制和去中心化的快速响应:中央规划器提前生成“网络意图”并推送到各交换机,当链路故障发生时,交换机可自主决策,避免依赖中央控制器。相比传统的BGP、OSPF等协议,SIDR在AWS的10p10u网络中能在不到1秒内恢复网络,速度比传统方法快10倍,显著提升了分布式AI训练中的可靠性和实时性,确保网络在故障发生时也能保持高效运行。
算力承载创新——全新数据中心组件
数据中心是算力的物理承载,也直观反应AI带来的计算变革。
据IDC圈了解,传统数据中心内以4kW、6kW、8kW机架为主,采用风冷散热,建设周期长,主要依赖人工巡检,运维难度和故障率高。可以说,从设计施工、再到运营运维,制冷以及成本等方面,均不符合当前生成式AI的需求。
作为全球云计算的开创者和引领者,亚马逊云科技在全世界范围内运营海量数据中心,直面生成式AI发展带来的需求与挑战,进行了数据中心层面的诸多创新,包括电源、冷却和硬件设计等层面。
随着生成式AI的日益普及以及客户对GPU容量需求的不断增长,亚马逊云科技不断调整和优化数据中心,以支持更高的功率密度需求
本次会上,亚马逊云科技宣布,推出一系列数据中心新组件,以支持新一代AI创新,满足客户对GPU容量需求的不断增长,支持更高的功率密度需求。
供配电:简化电气和机械设计,提高可用性
在数据中心内,电力强弱电转换和分配均伴随能源损耗和设备故障风险,简化的电气和机械设计更可靠,并易于维护,能确保客户受益于高可用性。
因此,亚马逊云科技在最新的数据中心设计优化中,采用了简化的电力分配和机械系统,实现基础设施的可用性达99.9999%,还将可能受到电气问题影响的机架数量减少89%。简化的电力分配系统,将潜在故障点的数量减少了20%;此外在实践中,亚马逊云科技将备用电源更紧密地集成至机架附近,并减少排热风扇的数量,使用自然压差来排出热空气,提高了服务器的可用电力。诸多改进措施不仅显著降低了整体能耗,还最大限度地减少了故障风险。
散热:更高效更灵活的液体冷却
随着生成式AI发展,芯片不断演进、功率快速攀升,高功率带来服务器和机架高热量,传统风冷已经无法满足数据中心的散热需求。亚马逊云科技与领先的芯片制造商合作开发了一项先进的机械冷却方案——“液体到芯片”的冷却系统。鉴于一些亚马逊云科技技术不需要液冷——如网络和存储,因此该冷却系统无缝集成空气和液冷,用于支持包括如Amazon Trainium2的强大AI芯片系列,NVIDIA GB200 NVL72等机架级AI超级计算解决方案。这样无论是运行传统工作负载还是AI模型,这一灵活的多模式冷却设计均能以最低成本提供最佳性能的散热服务。
机房部署:更高密度的机架布局
如前面所说,承载AI的服务器功率更高,单机架功率密度更大,对机房内机架布局带来挑战。亚马逊云科技通过软件优化数据中心的机架布局,最大化电力使用效率,该软件由数据和生成式AI驱动,能够精确预测服务器的最佳部署方式。据悉,通过在电力传输系统上和工程的突破,亚马逊云科技在未来两年内能够将机架功率密度提升6倍,并有望在未来进一步提升3倍。这不仅意味着亚马逊云科技数据中心计算能力大大增加,也意味着提供同等算力情况下,所需的数据中心数量也更少。
运维管理:更智能的控制系统
亚马逊新推出自主研发的控制系统,已应用于亚马逊云科技的电气与机械设备中,实现了监控、报警和运营流程的标准化。例如,利用亚马逊云科技内部构建的遥测工具使用亚马逊云科技的技术,能够提供实时诊断和故障排除服务,这些服务确保客户保持最佳运行状态。此外,亚马逊云科技在提升控制系统冗余度的同时,也简化了系统复杂性。这些改进使得亚马逊云科技基础设施可用性设计达到99.9999%。
能效:多措并举更低碳
算力规模快速增长的同时,能源与水资源消耗猛增,当前全球算力增长与能源矛盾愈发突出。亚马逊云科技推出的数据中心新组建,通过多方面举措,提升能源利用效率,降低碳排放。例如在建设阶段降低建筑外壳混凝土的固有碳排放量,较行业平均水平最高可降低35%;设计了更高效的冷却系统,运行高峰期相较于前一代设计的机械能耗降低46%,同时每MW用水量不变;备用发电机采用可再生柴油,为可生物降解且无毒的燃料,与传统的化石柴油相比,全生命周期内的温室气体排放量可减少高达90%。
上述数据中心新组件将在亚马逊云科技全球基础设施进行部署,覆盖全球34个区域、108个可用区。
生成式AI正在办公、零售、客服、金融、营销、文娱等领域加速落地,有业内人士预测“如果说2024是百模大战,那2025将是应用大战,也是Agent智能体的爆发之年”。
今天,千行百业面对这场生成式AI浪潮,恰如面对曾经的云计算浪潮,蕴藏机遇也面临挑战。从2024亚马逊云科技re:Invent 全球大会来看,作为全球云计算的开创者和引领者,亚马逊云科技正以全栈联动的大规模创新,做全球企业构建和应用生成式AI的首选。
正如亚马逊云科技大中华区产品部总经理陈晓建所说:“我们不仅在云的核心服务层面持续创新,更在从芯片到模型,再到应用的每一个技术堆栈取得突破,让不同层级的创新相互赋能、协同进化”
从多模态大模型及应用,到领先的AI基础设施创新,亚马逊云科技已经做好准备,也让我们对未来充满期待。
